

1. 서 론
2. 딥러닝 자동 영역 분류 기법(Deep learning instance segmentation network)
3. 비탈면 영상 자료 수집 및 학습 데이터셋 제작
3.1 비탈면 현장 영상 자료
3.2 비탈면 지반 자동분류 대상 지반 클래스 정의
4. 딥러닝 학습
4.1 비탈면 붕괴영상 데이터셋
4.2 실험 조건 및 평가방법
5. 딥러닝 학습결과 분석
5.1 실험 결과
5.2 비탈면 붕괴영상 추론 샘플 분석
6. 결 론
1. 서 론
비탈면은 자연적으로 존재하는 자연비탈면과 깎거나 쌓아서 인공적으로 조성된 인공비탈면으로 구분할 수 있으며 도로, 철도 선로, 건설재료 및 부지 등의 확보를 위한 목적으로 조성된다(MLTMA, 2011). 자연비탈면과 깎아서 조성된 인공비탈면은 일반적으로 불균질한 토양과 암반으로 구성되어 있고, 암반 불연속면의 상태와 방향성에 민감하며, 강우 등의 기상상태와 지진 등의 지반 현상에 대해 항시 중대형 붕괴 위험이 존재한다(Park et al., 2006). 따라서 비탈면 안정성 평가를 통해 사전에 붕괴위험 요인을 파악하고 이에 적절한 대응책을 수립해야 하며, 비탈면을 시공한 이후에는 꾸준히 모니터링 및 유지보수를 통해 비탈면을 관리해야 한다(MLTMA, 2011). 중대형 비탈면 붕괴 사고를 방지하기 위한 비탈면의 안정성 평가는 매우 중요한 과정이며, 이를 위해 시추조사 및 물리탐사 방법뿐만 아니라 육안관찰 및 영상분석 등을 통해 보다 정확하고 일관성 있는 비탈면 안정성 평가를 수행하고 있다. 일반적으로 비탈면 안정성 평가에서는 우선적으로 지반이 노출된 부분에 대하여 육안관찰을 통해 토양 및 암반의 분포 특성, 비탈면 지반의 풍화정도와 암반 절리 분포 특성을 파악하며 스케치하고, 비탈면의 높이 및 경사를 측정하여 그 형태와 특징들을 기록하는 비탈면 매핑작업을 시행한다. 그 다음, 평사투영법 등의 방법을 이용하여 구체 상에 암반 절리, 층리, 단층 등 불연속면이 발생한 지점들과 비탈면의 주향 및 경사를 투영함으로써 비탈면의 붕괴 가능성과 발생 가능한 붕괴유형 등을 예측키 위한 현장자료 분석을 수행할 수 있다. 이러한 정보들을 바탕으로 수치해석 모델링을 통해 비탈면 안정성을 해석을 실시하면 시간이 지남에 따라 비탈면이 어떠한 유형으로 거동하고 가능한 파괴 유형들을 상세 계산하고 분석할 수 있다(Kim et al., 2008).
기존 비탈면 안정성 평가는 비탈면 전문가들에 의해 진행되는데, 전문가마다 각자의 주관에 의해 평가되므로 비탈면 현장에 따라 일관성이 떨어질 수 있으며, 많은 비용과 시간이 소요된다. 이에 2018년에는 드론으로 촬영한 암반 비탈면 영상을 바탕으로 영상처리 알고리즘을 통해 영상을 보정한 후, 비탈면 지반 구조를 자동으로 분류하는 연구가 진행된 바 있다(Zhao, 2018). Zhao(2018)는 노천 광산 및 채석장의 비탈면 영상을 촬영하였으며, 비탈면 상공에서 드론으로 촬영하였으므로 태양빛에 의한 그림자의 영향을 받았으나, 인력이 접근할 수 없는 비탈면 영역을 쉽게 접근할 수 있으므로 가까운 상공에서 선명한 비탈면 영상을 얻을 수 있다. 드론 영상을 바탕으로 밝기 및 대비 조정을 통해 촬영 비탈면 영상 내의 그림자 영역을 제거하는 영상처리 과정을 거쳐, RGB영상에서 흑백 영상으로 변환한 다음, 소프트웨어를 통해 암반 비탈면에서 나타날 수 있는 암반 비탈면 불연속면의 크기 및 위치를 알 수 있는 영상을 추출하였다. 그러나 영상처리 알고리즘으로 영상을 보정하므로 영상의 해상도, 선명도 및 노이즈 등의 조건에 매우 의존적인 특징을 갖는다. 그리고 영상에서 암반 불연속면에 대한 개별적인 정보를 알 수 없고 하나의 프로그램이 아닌 영상처리 프로그램, 암반 비탈면 불연속면 추출 프로그램, 암반 불연속면 구조식별 프로그램 및 암반 비탈면 안정성 분석 프로그램 순서로 분석을 수행하므로 분석 절차가 복잡하다는 한계점이 존재한다.
본 연구는 기존 연구에 실시간 대응성을 강화하고, 영상 해상도 조건 및 그림자 조건과 상관없이 보다 일관성 있는 비탈면 매핑 작업을 자동으로 수행하기 위한 연구를 시도한다. 이를 위한 일환으로, 딥러닝 학습을 통해 토양 및 절리 암반면을 분류해 내고, 누수지점 및 부분 함몰영역 등 비탈면 지반 특성화 영역들을 자동 구분하고 분할할 수 있는 딥러닝 영상처리 기법을 제안한다. 이에 따라 국내 도로 현장에서 촬영된 실제 비탈면 현장영상으로 딥러닝 학습 데이터셋을 구성하여 학습하며, 학습하지 않은 비탈면영상에 대한 영역 분류 추론 결과 분석을 수행하고, 제안 기법의 성능과 현장 적용 가능성을 고찰해 보고자 한다.
2. 딥러닝 자동 영역 분류 기법(Deep learning instance segmentation network)
딥러닝은 기계학습(Machine learning)분류에 포함된 최신 인공지능 학습 분야의 하나로, 기계학습보다 깊고 복잡하게 구성된 모델이 입력값과 출력값이 포함된 데이터셋으로 학습할 수 있다(LeCun et al., 2015). 2019년 현재를 기준으로 음성인식, 영상 분류 및 추천 시스템 등에서 두각을 나타내고 있으며, 딥러닝 모델의 성능 향상에 대한 연구와 실생활에 적용하기 위한 응용 연구 모두 매우 활발하게 이루어지고 있다. 전통적인 기계학습은 모델의 구조가 단순하기 때문에 입력값도 수동으로 전처리를 통해 단순화해야 적절한 결과를 얻을 수 있지만, 딥러닝은 전처리를 거치지 않아도 복잡한 형태의 입력값을 학습하는 것이 가능하므로 딥러닝 기반 시스템의 일관성 및 성능이 기계학습보다 뛰어나다.
기계학습이 활발하게 연구되던 1980년대와 2010년대를 고려했을 때, 1980년대에는 하드웨어의 제약 및 과적합 (Overfitting) 등 한계점으로 인해 기계학습 모델의 규모를 크게 키우지 못하였다(Srivastava et al., 2014). 그러나 2010년대에 들어서기 시작하면서 그래픽카드(GPU)를 활용하여 복잡한 구조의 딥러닝 모델을 빠르게 구현하는 것이 가능하였고(Krizhevsky et al., 2012), Dropout(Srivastava et al., 2014), Relu(Nair et al., 2010) 및 Batch normalization(Ioffe and Szegedy, 2015) 등의 방법을 통해 과적합의 방지 및 딥러닝 모델의 효율적인 학습이 가능해지면서 인공지능 학습 분야는 딥러닝이라는 이름으로 다시 급격히 활성화되어, 2019년 현재 세계 각국에서 경쟁적으로 다양한 분야에서 활용할 수 있는 모델들이 활발히 제안되고 있다.
딥러닝의 발전은 컴퓨터 비전 분야에서도 매우 큰 영향을 끼쳤다. 기존 컴퓨터 비전 분야에서 진행되었던 연구는 주로 영상 분류 및 객체 인식 등 영상에서 단순한 정보를 얻는 것이었는데, 딥러닝으로 이러한 연구들에서 매우 정확한 분류 및 인식성능을 달성하는 것이 가능함을 보였다(Voulodimos et al., 2018). 컴퓨터 비전 학계에서는 딥러닝의 무한한 잠재력을 바탕으로 영상에서 어려운 정보를 인식하는 연구 목표들을 제시하였으며, 2015년에 처음 제안된 인스턴스 분할(Instance segmentation)기법은 그 중 하나이다(Lin et al., 2014).
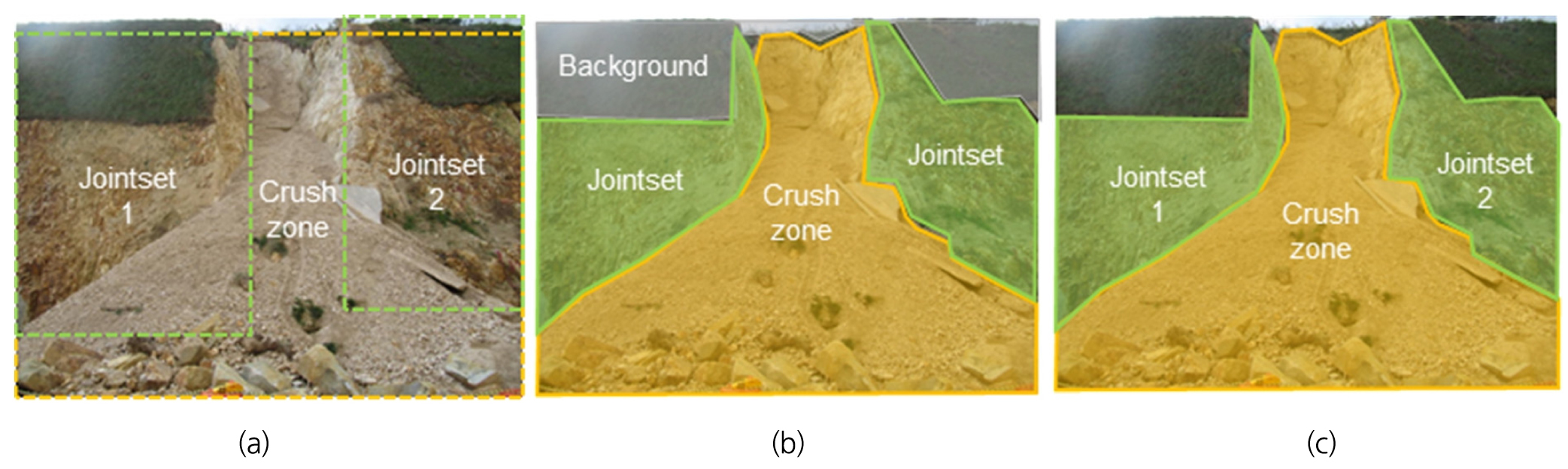
Fig. 1.
Three computer vision tasks for slope ground characteristic recognition (KICT, 2016) (a) object detection (b) semantic segmentation (c) instance segmentation
Fig. 1은 컴퓨터 비전 분야에서 비탈면 지반특성을 인식하기 위한 3가지 방법인 객체인식, 시멘틱 분할기법(semantic segmentation)과 인스턴스 분할기법(instance segmentation)을 표현한 그림들이다. 객체인식은 Fig. 1(a)와 같이 점선의 직사각형 형태인 경계박스(Bounding box)로 표현할 수 있으며, 직사각형의 일정한 형태로 검출하므로 후술할 시멘틱 분할기법과 인스턴스 분할기법보다 쉬운 방법론으로 볼 수 있다. 딥러닝 분야에서 자율주행 및 보행자 인식 등에 활용하기 위해 활발하게 연구가 이루어지고 있지만, 배경까지 포함하기 때문에 객체모양을 정확하게 인식하기 힘들다는 한계점이 있다.
시멘틱 분할기법은 Fig. 1(b)와 같이 영상에서 픽셀 단위로 객체의 모양을 정확하게 분리한 다음, 각각의 객체가 어떤 종류에 속하는지 구분한다. 객체인식과 비교하면, 시멘틱 분할기법은 정확하게 객체의 모양을 분리할 수 있지만, 개별적으로 객체의 정보를 파악할 수 있는 객체인식과 달리 객체의 종류만 알 수 있다.
인스턴스 분할기법은 Fig. 1(c)와 같이 객체모양을 정확하게 분리하여 표현 가능하며, 객체인식과 똑같이 개별적으로 객체의 정보를 파악할 수 있다. 그렇기 때문에 객체인식이나 시멘틱 분할기법보다 더 어렵지만 각 객체의 면적 및 위치 등의 정보를 활용할 수 있으므로 본 논문에서 지향하는 목표인 비탈면 지반특성 인식이나 균열 검출 등 세밀한 정보가 필요한 분야에 적용가능하다는 이점이 있다. 특히 인스턴스 분할기법으로 영상에서 비탈면 지반특성 정보를 얻게 되면 영상의 좌표계에서 실제 지형의 좌표계로 변환을 통해 비탈면에 나타나는 암반 불연속면의 길이, 간극 및 간격 등의 실제 정보를 계산하는 것이 가능하며, 비탈면 안정성 평가를 진행할 때 중요한 자료로 활용할 수 있다(Kim et al., 2001).
상기 항목에서 설명했듯이, 인스턴스 분할기법은 컴퓨터 비전 분야에서도 매우 어려운 연구 목표이다. 그렇기 때문에 인스턴스 분할기법을 제대로 수행할 수 있는 딥러닝 모델에 대한 연구들이 진행되었는데, 2017년에 등장한 Mask R-CNN(Region-based convolutional neural network) 알고리즘은 당시 획기적으로 높은 정확도를 선보이며 많은 연구자들의 주목을 받았다(He et al., 2017). Mask R-CNN은 Fig. 2와 같이 영상을 입력받아 영상의 특징도 추출, 특징도(Feature map)에서 영역 제안, 그리고 영역 분리, 직사각형 경계박스 회귀 및 객체 클래스 분류과정으로 진행된다.
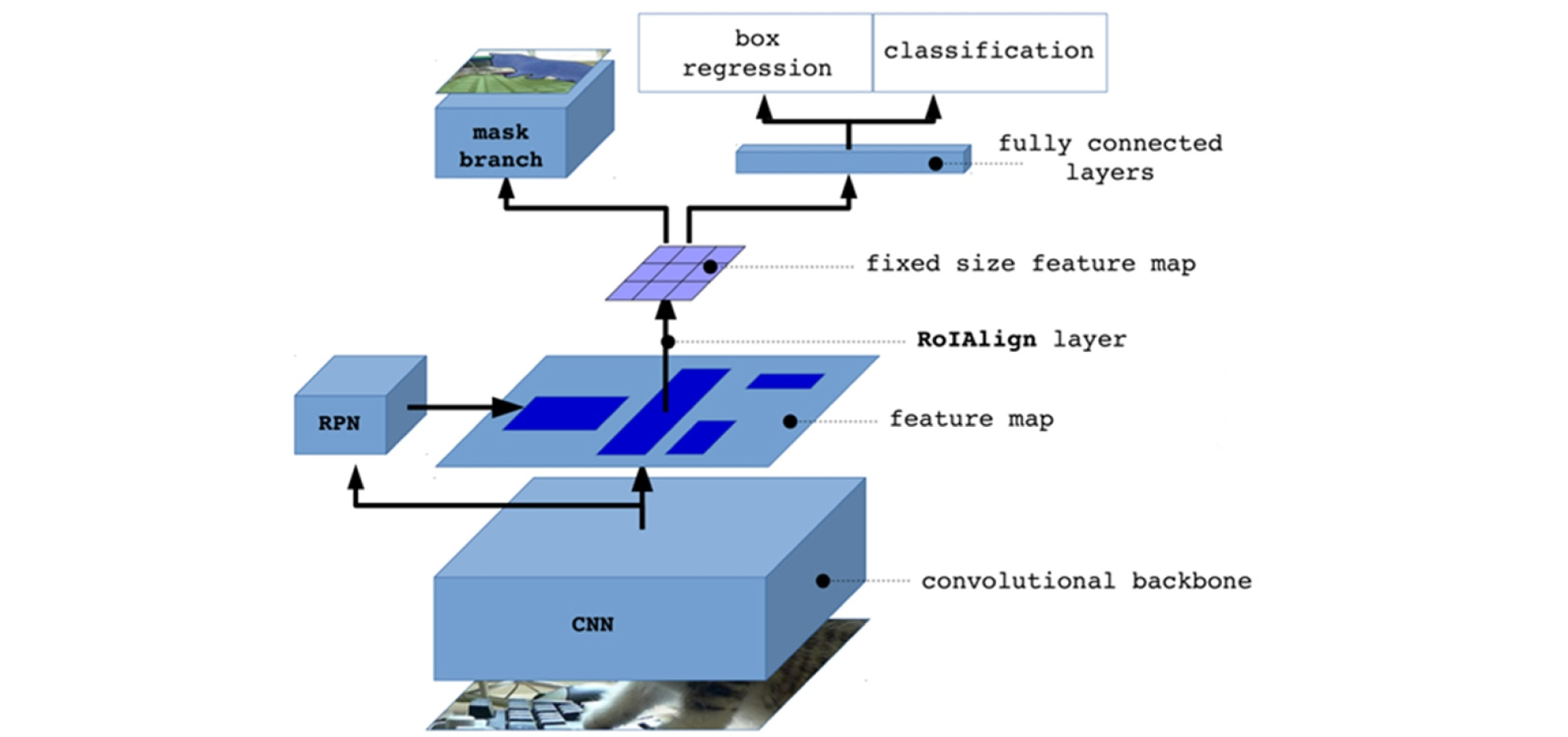
Fig. 2는 Mask R-CNN이 영상을 입력값으로 받은 다음 어떻게 인스턴스 분할기법을 구현하는지 나타낸 것이다. Mask R-CNN은 먼저 합성곱 인공신경망(Convolutional Neural Network, CNN)을 통해 영상으로부터 특징도를 추출하며, 특징도에서 Region Proposal Network(RPN)은 객체가 있을 만한 위치를 찾아서 수천 개의 영역들을 직사각형의 형태로 제안한다(Ren et al., 2015). 제안된 영역들은 관심영역 정렬층(RoI align)을 통해 고정된 형태의 특징도(Fixed size feature map)로 변환되며, 합성곱 층(Convolutional layer)로 구성된 마스크 브랜치(Mask branch)를 통해 객체모양을 정확하게 분리한다. 그리고 완전 연결층 (Fully-connected layer)은 깊은 구조의 인공신경망 층을 말하며, 직사각형 형태의 경계박스 (Bounding Box)와 객체의 클래스를 출력할 수 있다(Ren et al., 2015).
Mask R-CNN의 가장 큰 특징은 특징도 추출, 특징도에서 영역 제안, 그리고 영역 분리, 직사각형 경계박스 회귀 및 객체 클래스 분류과정이 모두 딥러닝 네트워크에 속하며, 학습이 가능하다는 것이다. 영상처리 알고리즘과 비교했을 때, 네트워크의 구조가 어느 데이터에 특화되지 않으며, 인식 목표 데이터셋의 구성에 따라 딥러닝 모델의 개선이 용이하다는 장점이 있다. 이러한 장점은 비탈면 붕괴영상을 바탕으로 데이터셋을 구성한 다음, 딥러닝 모델의 학습을 통해 본 논문의 목표인 비탈면의 지반특성 자동분류를 달성할 수 있을 것이다.
3. 비탈면 영상 자료 수집 및 학습 데이터셋 제작
3.1 비탈면 현장 영상 자료
딥러닝 모델을 바탕으로 비탈면의 지반특성 자동분류를 하려면 먼저 비탈면 붕괴영상을 수집한 다음, 분류를 위한 비탈면 지반 특성화 영역(class)들을 사전에 정의하고, 기 확보된 모든 비탈면영상에 보여지는 모든 지반 특성화 영역을 대해 레이블링 작업을 진행해야 한다. 본 논문에서는 단일 비탈면 시공 지역에 대한 데이터셋을 활용하여 레이블링을 진행하였으며, 딥러닝 모델의 학습과 검증에 활용하였다.
본 연구에 활용된 비탈면 현장은 OO도로 시공 현장이며,해당 도로 시공구간의 5개 비탈면에 대해 드론 및 인력을 통해 다각도에서 동영상으로 촬영하였다. 본 논문은 Fig. 2와 같이 CNN이 다양한 영상들의 특징을 추출하도록 학습하는 것이 가능하므로 딥러닝 모델의 범용성을 높이기 위해 드론과 인력이 촬영한 영상들을 구분 없이 모두 딥러닝 모델 구성에 활용하였다. 5개의 비탈면 지역에서 촬영된 영상은 정지영상 기준으로 총 681장이며, Fig. 3과 같이 드론촬영은 상공에서, 인력촬영은 지상에서 비탈면 촬영을 시행하였다.
Fig. 3(a)는 붕괴된 비탈면을 드론이 촬영한 사진으로, 한 눈에 비탈면 붕괴현황을 파악할 수 있다. 또한, 인력이 접근하기 힘든 지역에 가까이 접근하여 촬영할 수 있다는 이점이 있다(Zhao, 2018). Fig. 3(b)와 같이 인력으로 비탈면현장을 촬영한 경우, 드론으로 촬영한 영상과 비교했을 때 비탈면현장 전체를 촬영하기 힘들기 때문에 비탈면현장의 일부를 카메라로 근접 촬영한 영상이 다수이다. 그럼에도 불구하고 현재 인력에 의해 촬영된 비탈면 붕괴영상이 다수 존재하므로 데이터셋에 인력으로 촬영된 영상을 포함하여 딥러닝 모델의 학습에 반영하였다.

3.2 비탈면 지반 자동분류 대상 지반 클래스 정의
본 논문에서는 딥러닝 학습 대상 지반 자동분류 대상 객체 클래스인 암반 절리군, 암반 단층, 토양, 비탈면 붕괴영역 및 비탈면 누수영역을 선정하여 비탈면 붕괴영상의 레이블링을 진행하였다. 영상의 레이블링 작업은 COCO Annotator 웹 기반 레이블링 프로그램을 활용하였으며, 정지영상 기준으로 기 정의된 클래스 객체의 영역을 다각형의 형태로 그리는 작업을 진행하였다 (Brooks, 2019).
절리 암반(Rockmass jointset) 영역은 절리가 발달된 암반체로 정의하였으며, 절리의 방향성과 간격 등의 절리 정보를 특성화 하지는 않았으며, 절리가 발달된 암반 영역으로 단순화해 하나의 분류 클래스로 정의하였다. 본 논문에서는 인스턴스 분류기법을 기반으로 연구를 진행하므로 절리군의 방향성을 고려하지 않고 암반 절리군 영역을 인식하는 것에 초점을 맞추었다. 이후, 보다 세분화된 절리암반체의 특성 정보를 얻기 위한 연구가 진행될 계획이다.
암반 단층 (Rockmass fault)은 어느 면을 경계로 양쪽 암반에 변위가 발생한 불연속면을 말하며, 비탈면의 붕괴에 큰 영향을 미치므로 반드시 인식하여 분류해야 하는 분류 클래스이다. 그런데, 영상에서 단층은 대부분 선의 형태로 관찰되므로 영역을 인식하는 것이 목적인 인스턴스 분류기법을 적용하기 위해 암반 단층을 대상으로 레이블링을 진행하여도 제대로 인식하지 못할 가능성이 있다. 따라서 본 논문은 암반 단층에 대하여 단층선 주변의 영역까지 포함하여 레이블링을 진행하였으며, 결과적으로 암반 단층은 발달방향으로 길쭉한 영역의 형태로 레이블링된다.
토양(Soil)은 비탈면에서 취약한 요소로 판단할 수 있으며, 강우 및 지진 등의 자연재해로 비탈면이 붕괴될 수 있으므로 본 논문의 인식 목표중 하나로 선정하였다. 그런데, 비탈면에서 풍화된 암반이 존재하기 때문에 영상에서 토양과 풍화된 암반을 구별하는 것은 쉽지 않으므로 시공현장 보고서에서 각 비탈면 현장에 대한 도면을 참조하여 토양의 위치를 파악한 후, 레이블링을 진행하였다.
비탈면 붕괴영역(Crush zone)은 영상에서 비탈면이 부분적으로 함몰된 영역을 말한다. 비탈면 붕괴영역을 방치할 경우, 비탈면 붕괴영역의 규모가 커지므로 붕괴영역의 인식 및 보강이 필요하다 (Park et al., 2006). 비탈면 붕괴영역은 영상에서 육안 상으로 명백하게 확인 가능하므로 레이블링이 수월하며, 각 비탈면 현장에 대한 도면을 참조하여 비탈면 붕괴영역의 존재유무를 판단하여 레이블링을 진행하였다.
비탈면 누수영역(Leakage water)은 비탈면 현장에서 지하수 또는 흐르는 물에 의해 누수되고 있는 영역을 말한다. 비탈면은 암반 불연속면이나 토양에서 누수로 인해 매우 불안정해지며, 붕괴될 가능성이 상승하기 때문에 반드시 인식할 수 있어야 한다 (Park et al., 2006). 비탈면 누수영역의 레이블링은 비탈면을 부분적으로 촬영한 영상에서 명백하게 젖어있는 영역과 각 비탈면 현장에 대한 도면에 기록된 누수지점을 참조하였다.
Fig. 4는 상기 설명한 내용을 바탕으로 COCO Annotator를 활용하여 암반 절리군, 암반 단층, 토양, 비탈면 붕괴영역 및 비탈면 누수영역 클래스를 레이블링한 영상 샘플들이며, 암반 절리군은 초록색, 암반 단층은 빨간색, 토양은 노란색, 비탈면 붕괴영역은 주황색, 그리고 누수영역은 하늘색으로 구분하여 레이블링을 진행하였다.
Fig. 4(a)에서 암반 절리군은 영상에서 암반임이 명확하며, 절리들이 표현된 영역을 레이블링하였다. 암반 단층은 영상에서 암반층이 균열을 기준으로 명확하게 나누어 졌을 때, 균열에 해당하는 영역을 레이블링하였으며, 단층선 주변의 영역까지 포함하여 레이블링을 진행하였다. 토양은 영상에서 토양으로 관찰된 영역을 레이블링하였으며, 마지막으로 Fig. 6(b)는 암반 또는 토양여부에 상관없이, 비탈면 영역에서 물이 흐르거나 젖은 영역을 레이블링하였다.

4. 딥러닝 학습
상기 설명한 비탈면 지반분류 대상 객체 클래스들을 인식하기 위한 영상 데이터셋을 준비한 다음, 딥러닝 모델의 인식능력을 검증하기 위한 실험을 진행하였다. 이에 맞추어 딥러닝 모델의 학습조건 및 환경을 설정한 다음, 추론성능을 검토하였다.
4.1 비탈면 붕괴영상 데이터셋
본 논문은 681개의 비탈면 붕괴영상들을 바탕으로 레이블링 및 데이터셋 구성을 진행하였으며, Table 1와 같이 딥러닝 모델의 학습을 위한 데이터셋을 구성하였다.
Table 1. Composition of deep learning datasets
| Dataset | Number of images | Number of objects | ||||
| Rockmass jointset | Rockmass fault | Soil | Crush zone | Leakage water | ||
| Training dataset | 612 | 987 | 198 | 132 | 326 | 79 |
| Validation dataset | 69 | 98 | 15 | 11 | 31 | 4 |
Table 1은 딥러닝 모델을 학습할 비탈면 붕괴영상 데이터셋의 현황을 나타내었다. 데이터셋에 대한 딥러닝 모델의 과적합을 피하기 위해 전체 681개의 비탈면 붕괴영상에서 학습 및 검증용 데이터셋을 9:1의 비율로 임의로 나누었다. 각 데이터셋에서 객체수는 암반 절리군, 비탈면 붕괴영역, 암반 단층, 토양 및 누수영역 순서로 다수 존재하였다. 누수영역의 경우, 전체 비탈면 붕괴현장에서 누수 지점이 희귀하게 존재하기 때문에 가장 적은 비율로 객체수가 존재한다.
4.2 실험 조건 및 평가방법
4.2.1 딥러닝 모델 학습 조건 및 환경
딥러닝 모델을 학습하기 위해서는 해당 딥러닝 모델에 대한 최적의 학습상수를 설정한 다음 학습할 수 있어야 한다. 그런데, 아무런 배경 없이 딥러닝 모델에 대한 최적의 학습상수를 설정하는 연구는 상당한 시간이 소요되므로 본 논문에서는 Table 2와 같이 Mask R-CNN 딥러닝 모델에 대하여 이미 검증된 최적의 학습 상수값으로 설정하였다 (He et al., 2017).
본 논문에서는 Mask R-CNN을 활용하므로 영상의 특징을 추출하는 합성곱 인공신경망이 중요한 역할을 하며, 50층의 Residual network를 사용한다. Residual network는 기존 합성곱 인공신경망과 다르게 일부 합성곱층만 거치는 구조이며, 이미지 분류에서 매우 우수한 성능을 보인다(He et al., 2016). 학습반복회수(Epoch)와 학습율(Learning rate)은 Mask R-CNN 논문에서 사용했던 최적값을 그대로 사용했으며, 영상배치크기(Image batch size)는 1장으로 설정하여, 매 영상마다 학습과 가중치 업데이트가 이루어 진다.
Table 2. Deep learning management parameters
| Category | Information |
| Convolutional Network | Residual Network – 50 layer |
| Epoch | 160 |
| Learning rate | 0.001 |
| Image batch size | 1 |
Table 3. Deep learning management environments
| Category | Information |
| Operating system | Windows 10 |
| Programming language | Python 3.7 |
| Deep learning framework | Tensorflow 1.13.1 |
| CPU | Intel i5 8500 |
| GPU | Nvidia GTX 1070 Ti 8GB |
| Ram capacity | 8GB |
Table 3은 딥러닝 모델의 학습환경을 나타낸다. Windows 10에서 Python 3.7으로 딥러닝 모델을 실행하였으며, Tensorflow 1.13.1 버전의 딥러닝 프레임워크를 이용한다. 하드웨어의 경우, CPU는 6코어 6스레드인 Intel i5-8500, Ram capacity는 8GB, GPU는 Nvidia GTX 1070 Ti 8GB 2장을 학습에 활용하였으며, 딥러닝 코드의 구조상 CPU 및 RAM을 활용하므로 딥러닝 모델 및 데이터셋의 용량에 맞추어 CPU 및 RAM을 설정하였다.
4.2.2 딥러닝 모델의 평가 방법:Average Precision
상기 설명한 데이터셋, 학습 상수 및 환경을 설정하여 딥러닝 모델을 학습한 다음, 딥러닝 모델의 평가를 통해 검증하는 과정이 필요하다. 이에 따라 본 논문은 인스턴스 분류기법에서 참과 거짓을 정하는 기준인 Intersection over union (IoU)을 바탕으로 평가를 진행한다(Lin et al., 2014).
IoU는 비교대상 객체들이 겹치는 비율을 나타낸 값으로, 기준을 설정하여 일정 값 이상일 경우 참으로 판단하게 된다(Zitnick et al., 2014). Mask R-CNN은 영상에서 다중으로 인스턴스 분류기법을 인식하기 때문에 한 영상에 대한 딥러닝 모델의 출력값들과 데이터셋의 결과값을 비교하여 각 출력값마다 가장 높은 IoU값을 가진 경우들에 한정해서 참거짓을 판단한다.
각 출력값에 대한 판단은 IoU를 바탕으로 진행된다. 그러나 딥러닝 모델의 인식성능은 평균 정밀도 (Average precision, AP)를 바탕으로 판단한다. AP는 딥러닝 모델이 데이터셋을 인식할 때, 양적인 측면과 질적인 측면을 모두 고려하여 하나의 스칼라값으로 나타낼 수 있는 지표이다(Zhu, 2004). 각 객체 클래스마다 AP의 연산이 진행되며, 데이터셋 객체마다 IoU값을 기준으로 참거짓을 판단할 때, 객체들의 인식량만 평가하는 재현률 (Recall)과 정확도를 판단하는 정밀도 (Precision)를 계산할 수 있다. AP는 식 (1)과 같이 객체마다 계산된 재현률과 정밀도를 통해 적분값으로 표현할 수 있다.
| $$Average\;\mathrm{Precision}(AP)=\int_{}^{}{\mathrm{Prceision}(Recall)d(Recall)}$$ | (1) |
AP는 인스턴스 분류기법에서 딥러닝 모델의 인식성능을 하나의 값으로 간단하게 비교할 수 있으므로 컴퓨터 비전 분야에서 널리 사용되고 있는 지표이다. 이에 따라 본 논문에서도 지반특성의 인식을 위해 IoU 인식기준을 0.75로 설정한 다음, AP값을 기반으로 딥러닝 모델에 대한 평가를 진행하였다.
5. 딥러닝 학습결과 분석
5.1 실험 결과
딥러닝 모델의 학습은 Nvidia GTX 1070 Ti 8GB 2장을 기준으로 약 23시간 24분이 소요되었으며, AP값을 바탕으로 학습용 및 검증용 데이터셋마다 딥러닝 모델의 인식성능을 평가하였다. 그런데, 데이터셋의 평가는 상당한 시간이 소요되므로 본 논문에서는 10 Epoch마다 딥러닝 모델을 평가하였다. 그리고 인스턴스 분류기법 기준보다 더 쉬운 객체인식 기준을 포함하여 AP값의 평가 및 분석을 진행하였으며, Fig. 5와 같이 딥러닝 모델의 검증결과를 객체 클래스마다, 그리고 10 Epoch 학습 완료시 마다 그래프로 도시하였다. Fig. 5(a)와 Fig. 5(b)는 인스턴스 분류기법 기준으로 검증한 결과이고, Fig. 5(c)와 Fig. 5(d)는 객체인식 기준으로 검증한 결과이다. 그리고 Fig. 5(a)와 Fig. 5(c)는 학습용 데이터셋, Fig. 5(b)와 Fig. 5(d)는 학습에 사용하지 않은 검증용 데이터셋에 대한 추론 결과이다.
인스턴스 분류기법 기준으로 최종 학습 종료시점인 160 Epoch에서 딥러닝 모델의 추론결과를 살펴보면, 절리 암반 영역이 가장 높은 인식성능을 보였으며, 토양, 비탈면 붕괴영역, 누수영역과 암반 단층 순서로 높은 인식성능을 보였다. 암반 단층 영역에 대한 인스턴스 분류에서는 학습용 데이터셋과 검증용 데이터셋 모두 0부터 160 Epoch까지 AP값이 0이었으며, IoU 0.75기준을 넘는 영역 추론 데이터가 존재하지 않았음을 의미한다. 이는 실제 영역과 추론된 영역의 겹친 면적(IoU)과 연관되고, Fig. 4(a)와 같이 암반 단층 영역의 형상은 항시 선형의 얇고 길쭉한 영역 형상 특성을 가지므로 객체로서 영역은 인식되었음(Fig. 4(c)와 Fig. 4(d))에도 객체 영역 인식율에 대한 척도(AP값)의 계산은 어려웠음을 알 수 있다. 절리 암반 영역, 토양과 비탈면 붕괴영역은 비탈면 붕괴영상에서 큰 면적 비율로 객체가 존재하므로 무리없이 학습되어 높은 추론 성능을 보였음을 알 수 있다. 누수영역의 경우, 학습용 데이터셋에서 0.3, 추론용 데이터셋에서 0.7의 AP값을 보였는데, 누수영역의 형태가 비탈면 붕괴영상에서 작은 누수점의 형태로 존재하는 객체가 대부분이고 학습용 데이터셋에 대부분 포함되었으므로 딥러닝 모델이 인식하는데 상대적으로 어려움을 겪은 것으로 보인다. 반면에 추론용 데이터셋은 Fig. 4(b)와 같이 비탈면 붕괴현장을 부분 촬영한 영상에서 누수 영역 객체를 레이블링한 영상이 대부분이었으므로 추론용 데이터셋에서는 높은 AP값을 보였다.
객체인식 기준으로 딥러닝 모델의 검증결과를 살펴보면, 160 Epoch에서 딥러닝 모델의 인식성능은 암반 절리군, 토양, 비탈면 붕괴영역, 암반 단층 및 누수영역 순서로 높은 인식성능을 보였다. 암반 단층은 인스턴스 영역 분류와 다르게 Fig. 5(c)와 같이 0.6 이상의 높은 AP값을 보였는데, 경계박스의 형태로 딥러닝 모델이 암반 단층을 추론하는 것이 인스턴스 영역분류 결과와 비교하면 비교적 용이하게 추론할 수 있음을 의미한다.
전체적인 학습 경향을 감안하였을 때, Epoch가 증가할수록 AP값도 일정하게 증가하는 경향이었으며, 120 Epoch에서 최고 AP값에 도달한 이후 160 Epoch 이후에는 큰 AP값이 변화없이 수렴하는 경향을 보였다. 그리고 학습용 데이터셋은 일정하게 AP값이 증가하는 경향을 보였지만, 검증용 데이터셋은 절리 암반 영역을 제외하고 증가 및 감소를 반복하면서 AP값이 향상되었다. 딥러닝 모델은 검증용 데이터셋을 학습하지 않으며, 검증용 데이터셋에 포함된 객체 개수가 적기 때문에 이러한 경향을 보인 것으로 판단된다.
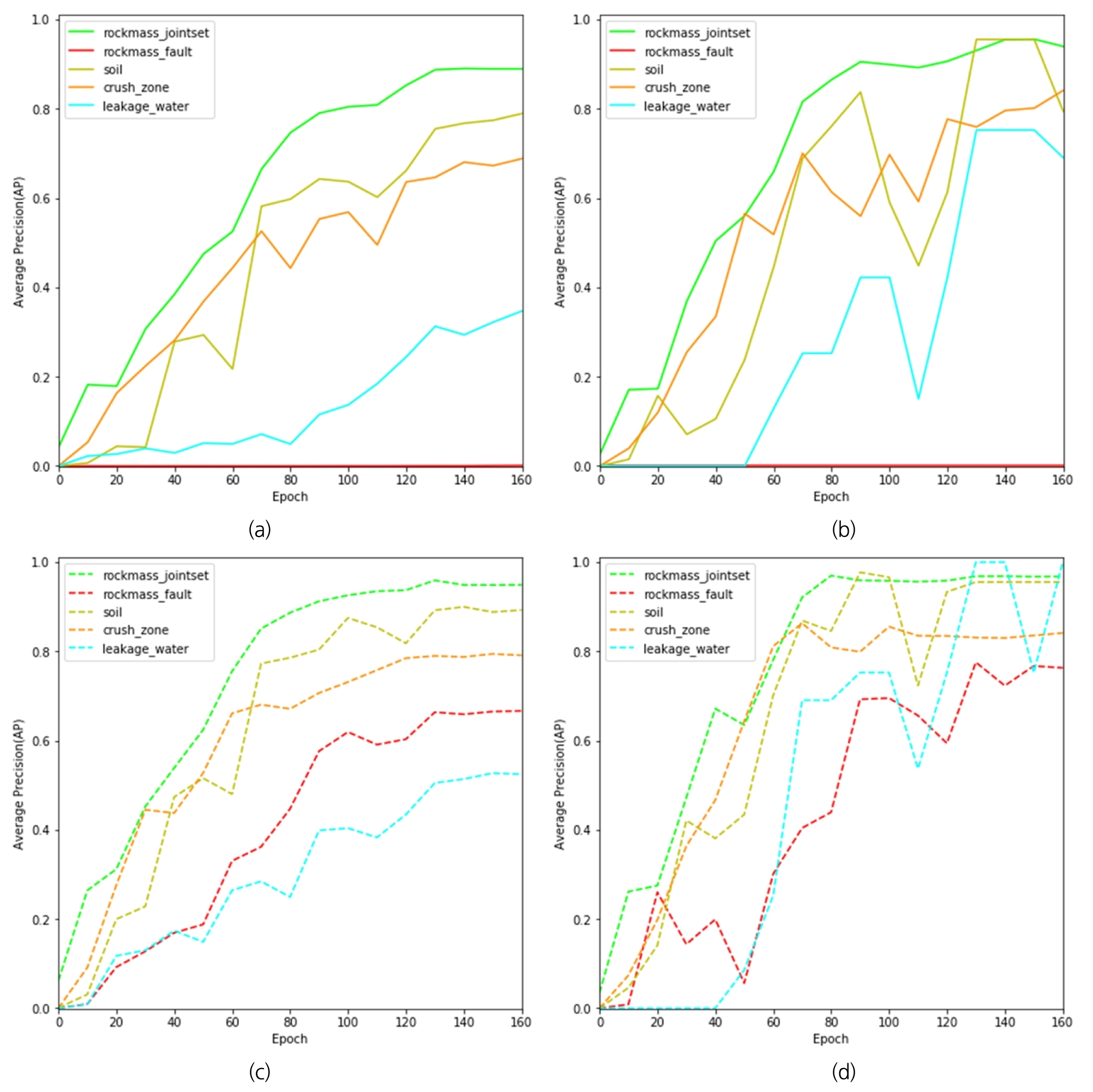
Fig. 5.
Deep learning validation results (a) Result for training dataset using instance segmentation standard (b) Result for validation dataset using instance segmentation standard (c) Result for training dataset using object detection standard (d) Result for validation dataset using object detection standard
5.2 비탈면 붕괴영상 추론 샘플 분석
딥러닝 모델에 대한 AP값을 평가하면 절리암반 영역, 비탈면 붕괴영역과 토양은 딥러닝 모델이 대체로 정확하게 객체모양을 추출한 것으로 판단할 수 있다. 누수영역은 정확도가 떨어진 편이지만, 딥러닝 모델을 통한 인식 가능성은 높아 보인다.
그런데, 암반 단층 영역의 객체인식은 대체로 높은 AP값을 보였지만 인스턴스 분류 결과에서 상대적으로 가시하기는 힘들었다. 이는 선형으로 길쭉한 영역 형태 특성에 기인한 것으로 판단된다. 그렇기 때문에 암반 단층의 인식목표는 영역이 아니라 선의 형태를 인식하는 것이므로 영상을 추론한 다음 시각화하여 암반 단층의 인식된 형태를 판단할 필요가 있다. 이에 따라 Fig. 6과 같이 추론 데이터의 시각화를 통해 암반 단층을 포함한 5개의 지반 특성화 영역 클래스들에 대한 딥러닝 모델의 인식능력을 판단하였다.
Fig. 6는 정의된 실제 영역과 추론된 영역을 겹쳐서 함께 표시한 그림이다. 4장의 영역추론 결과에서 딥러닝 모델은 객체 클래스들의 모양을 정확하게 인식하고 있으며, 특히 절리 암반 영역은 비탈면 붕괴영상마다 객체 영역 형상을 거의 완벽하게 인식하고 있다. 나머지 객체 클래스도 객체 형상을 대체로 정확하게 인식하였으며, 암반단층 또한 객체모양을 대체로 정확하게 인식한다. Fig. 6의 영상샘플들을 보면 딥러닝 모델이 거의 완벽하게 인식하고 있는 것으로 보이지만, IoU 기준으로 판단하면 참값이 아닐 수 있다. 따라서 딥러닝 모델의 추론데이터와 데이터셋을 비교하여 계산된 IoU가 실제 영상에서 어떻게 계산되는지 확인할 필요가 있다.
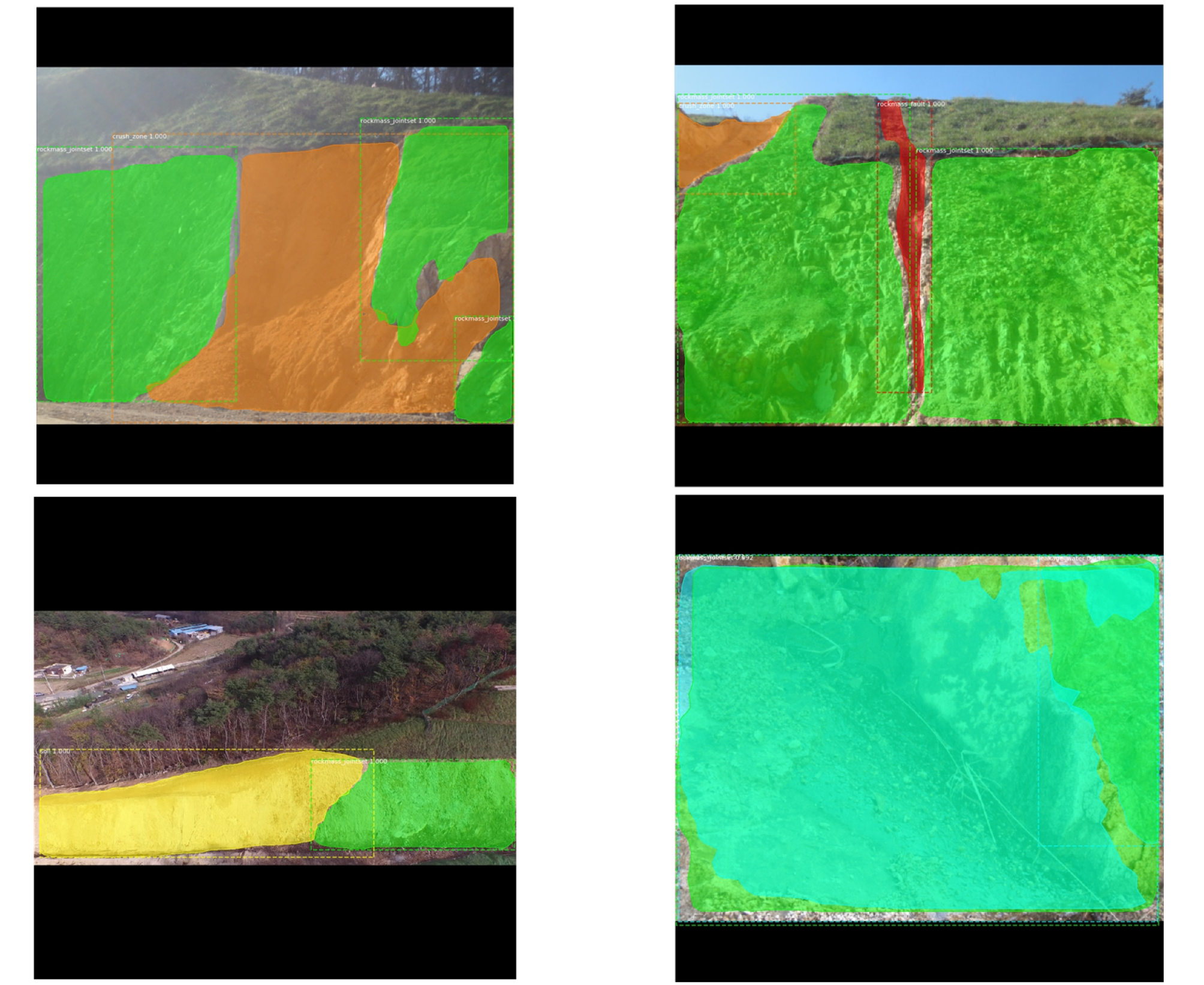
Fig. 7은 정의된 실제 영역(Green)과 추론된 영역(Red)를 겹쳐서 도시한 그림이다. 암반 단층 영역에 대한 추론은 Fig. 5(a)에서 AP값이 0이었지만, Fig. 7의 좌측 상단의 영상과 좌측 하단의 영상을 확인해보면 영상 중앙에서 인식된 암반 단층 영역의 데이터셋과 큰 차이없이 대체로 정확하게 인식하였음을 알 수 있다. 그런데 암반 단층은 인식된 객체모양의 크기가 조금만 작아져도 IoU값이 크게 작아지므로 IoU에 민감하며, 인스턴스 분류 기준으로 계산된 AP값이 0이 될 수밖에 없다. 나머지 4개의 자동인식 대상 클래스들의 경우, 대체로 객체의 크기가 크기 때문에 상기 언급된 AP값 계산상의 문제에는 둔감하므로 IoU 또한 0.9 이상으로 데이터셋과 가깝게 딥러닝 모델이 추론될 수 있었다.

6. 결 론
본 논문은 딥러닝 인스턴스 분류기법을 통해 비탈면의 지반특성 자동분류에 대한 연구를 수행하였으며, 5개의 자동인식 대상 클래스들에 대한 딥러닝 모델의 인식성능을 인스턴스 분류 기준과 객체인식 기준으로 평가하였다. 그 결과, 암반 절리군, 토양, 비탈면 붕괴영역과 누수영역은 영상의 해상도와 촬영지점의 위치/방향 등의 영상조건과 무관하여 인스턴스 분류가 가능함을 보였다. 그러나, 선형적으로 길쭉한 객체 형상 특성을 갖는 암반 단층은 객체 영역의 존재 유무는 정확히 인식되었지만, 그 형상을 정확히 추론하는데 한계가 있었다. 본 연구를 통해 다음과 같은 결론을 얻을 수 있다.
1) 본 연구에서는 절리가 발단된 암반영역, 토양 영역, 선형의 암반 단층 영역, 지하수가 흐르는 누수 영역, 부분 함몰 지반 영역 등 5개의 지반 특성화 영역에 대해 딥러닝 인스턴스 분류 알고리즘을 적용하여 자동 영역 분류를 시도하였으며, 높은 추론 성능으로 지반 특성화 영역 추론을 수행할 수 있음을 보였다. 딥러닝 기반 영역분류에서는 인력으로 가까운 거리에서 촬영된 영상이나 드론으로 먼 거리에서 촬영된 영상에 대해서도 동일한 수준의 높은 성능으로 영역 추론이 가능하였으며, 그림자 등의 노이즈 영역이 영상에 포함되어 있어도 정의된 클래스의 영역 분류에는 그리 영향을 미치지 않았다.
2) 그러나, 정의된 클래스의 영역 형상 특징에 따라 추론 성능 지표인 AP값 계산에는 영향을 미쳤다. 객체 모양이 작거나 얇고 긴 형태인 경우 딥러닝 모델을 인스턴스 분류 기준으로 계산된 IoU는 민감하게 변하며, AP를 계산할 때 IoU기준이 높으면 참값이 아예 존재하지 않을 수 있다. Fig. 5(a)와 Fig. 5(b)에서 암반 단층의 AP값은 0으로 전혀 인식하지 못했지만, Fig. 6의 우측 상단 영상과 같이 객체모양을 대체로 정확하게 인식한다. 그런데, 암반 단층의 지향점은 영역이 아닌 선을 인식하는 것이므로 AP가 0이 되어도 추론 데이터의 시각화 및 육안관찰을 통해 암반 단층을 선의 형태로 인식할 수 있다면 비탈면 지반특성의 자동 분류에 활용할 수 있다. 따라서 암반 단층의 인식성능을 평가하려면 IoU기준이 아닌 선을 인식할 수 있는 별도의 기준을 통해 평가해야 한다.
3) 본 논문에서 사용한 비탈면 붕괴영상 데이터의 규모는 영상 개수기준으로 볼 때, 일반적인 데이터셋 규모가 최소 5,000개 이상인 것을 고려하면 작다고 볼 수 있다. 따라서 후속 연구에서 다양한 비탈면 붕괴현장의 영상을 레이블링하여 데이터셋의 규모를 키워서 학습한다면 보다 신뢰성 있는 딥러닝 모델을 학습할 수 있을 것으로 판단된다.
상기 언급한 문제점을 보완하여 딥러닝 모델을 바탕으로 비탈면의 지반특성을 정확하게 분류할 수 있다면 비탈면 안정성 평가에 중요한 자료로 활용할 수 있으며, 이에 더 나아가 비탈면 현장에서 자동적으로 붕괴가능성을 평가할 수 있는 프로세스의 핵심 기능으로 역할을 할 수 있을 것이다.
