

1. 서 론
2. 재료 및 방법
2.1 시편 정보 및 3차원 X-ray CT 이미징
2.2 균열 추출을 위한 딥러닝
3. 학습 데이터 구성
3.1 학습 및 테스트 데이터 (Training and test data)
3.2 영상 데이터 증대
4. 결과 및 분석
4.1 최적의 학습 데이터셋 선정
4.2 테스트 데이터 (Test data)
5. 결 론
1. 서 론
암석 내 존재하는 불연속면은 역학적 안정성과 수리적 물성을 지배하는 요소로서 지하수 유동, 비전통 에너지 개발, 그리고 심부 지열발전 등에서 고려해야 하는 주요 인자이다. 특히 인공 지열 저류층 생성기술(Enhanced geothermal systems; EGS)과 같은 심부 지열발전 연구에서는 발전 효율을 증대시키기 위해 수리 자극(Hydraulic stimulation)으로 추가적인 암반 내 균열의 생성을 유도하게 된다(Jung et al., 2016). 이때 수리 자극으로 인해 발생하는 추가 균열은 암석의 구조적 특성과 응력 상태의 함수이며 발생한 균열의 빈도, 방향성, 연결성 등에 의해 투수 계수의 값이 결정된다 (Goodman, 1989). 따라서 많은 연구자들이 다양한 수리 자극 또는 수압파쇄 조건에서 발생하는 균열들을 특성화(characterization)하기 위해 실내 실험들을 수행하였으며(Bennour et al., 2015, Ha et al., 2018), 외부에서 볼 수 없는 암석 시편 내부에 발달한 균열을 특성화하기 위해 X-ray computed tomography(CT) 촬영을 수행하였다(Ketcham and Carlson, 2001, Jeong et al., 2017).
X-ray CT(이후 CT)로부터 획득되는 시편 내부의 영상은 16-bit 회색조(grayscale) 이미지이고 각각의 픽셀들은 해당 지점에서의 재료의 밀도와 유효 원자번호의 함수이다. 일반적으로 밀도가 낮을수록 낮은 밝깃값으로 밀도가 높을수록 높은 밝깃값으로 재구성(reconstruction)되며 영상 내에서 고체는 밝고 기존 공극이나 균열은 어둡게 표현된다. CT 영상 내 균열을 분리(segmentation)하기 위해서 전역 문턱치 처리(Global thresholding), 지역 적응형 문턱치 처리(Locally adaptive thresholding), 영역 확장(Region growing), 캐니 윤곽선 검출(Canny edge detection) 등의 전통적인 방법들이 적용 가능하였다(Schlüter et al., 2014, Iassonov et al., 2009, Liu et al., 2014, Bandyopadhyay et al., 2016). 하지만 CT 영상에서 수반되는 여러 노이즈들(ring artifact; high frequency noise; beam hardening 등)로 인해 전통적인 분리 방법들은 충분한 성능을 나타내지 못했다. 이는 기존의 방법들이 전역적/국부적 밝깃값 분포와 변화에만 의존하여 노이즈로 인해 성능이 현저히 감소하기 때문이다.
전통적인 영상처리 방법의 한계를 극복하기 위해 합성곱 신경망(Convolutional neural networks; CNN) 기반의 딥러닝 기술이 제안되었고, AlexNet(Krizhevsky et al., 2012), VGGNet(Simonyan et al., 2014), GoogLeNet(Szegedy et al., 2015), ResNet(He et al., 2016), Inception Net(Ioffe and Szegedy, 2015, Szegedy et al., 2016, Szegedy et al., 2017) 등 우수한 성능을 가진 CNN 모델들이 개발되었다. 개발된 딥러닝 구조들은 일반적인 사진/영상에서의 객체 인식에 뛰어난 성과를 보였으며, 최근에는 콘크리트 지반 구조물에서의 균열 탐지 및 분류(Cha et al., 2018, Yang et al., 2018, Li et al., 2019), 포장 도로 균열 탐지(Zhang et al., 2017, Bang et al., 2019) 등 다양한 토목 구조물의 사진/영상으로부터 신속하고 정확하게 균열을 추출하는 연구들이 발표되고 있다.
본 연구에서는 실내 수압파쇄 시험 후 미세균열이 발생한 화강암 시편을 대상으로 X-ray CT 영상을 촬영하고, CNN 기반 딥러닝 기술을 적용하여 CT 영상으로부터 미세균열을 분리하였다. 이를 위해 CNN 기반 딥러닝 모델 학습에 필요한 데이터를 생성하였으며 효율적인 학습을 위해 영상 증대(Image augmentation) 방법의 최적 조합을 분석하였다.
2. 재료 및 방법
2.1 시편 정보 및 3차원 X-ray CT 이미징
본 연구에서 사용된 시편은 포천 화강암으로 EGS 지열발전의 수압파쇄 연구에서 활용된 사례가 있다(Kang et al., 2014). 대상 시편은 직경 50 mm, 높이 100 mm의 원통형 시편이고, 수압파쇄 실험에서는 구속압력 5 MPa, 수직압력 10 MPa을 가한 상태에서 100 mm3/sec의 일정한 주입속도로 물을 주입하였다(Jung et al., 2016). 실험 후 구속압력 및 주입 유체의 압력이 소산된 상태에서 X-ray CT 촬영을 수행하였다(X-EYE PCT-G3). X-ray CT 촬영으로 획득된 영상은 1024×1024 크기의 2차원 영상이 1696장 적층된 형태로, 영상의 단위 픽셀 길이는 59 μm이다.
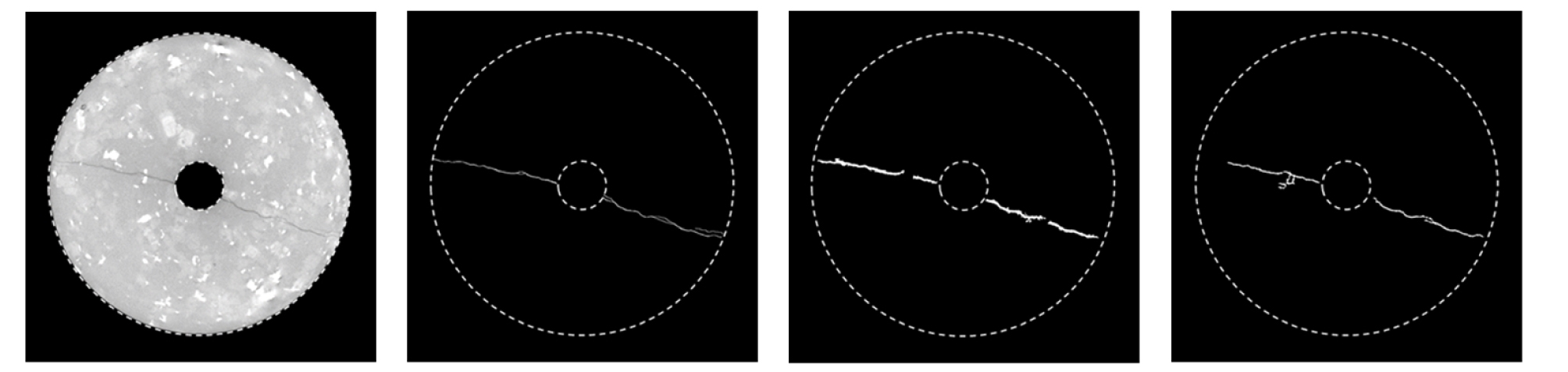
Fig. 1은 실험 후 시편의 CT 단면 영상으로 상단부를 보면 유체를 주입한 내공에서 외부로 미세하게 균열이 전파된 것을 알 수 있다. 전체 영상 크기에서는 미세균열은 손상되지 않은 주변 영역(intact zone)보다 상대적으로 어두워 보이지만 영상을 확대하면 노이즈와 픽셀 해상도 한계로 인해 균열과 주변 영역의 경계가 모호한(fuzzy) 상태임을 알 수 있다. Fig. 2(a)는 다른 지점에서의 시편 단면 영상이고 Fig. 1보다 균열이 뚜렷하게 나타나 있다. 전통적인 분리 방법들의 성능을 확인하기 위해 Fig. 2(a)로부터 균열을 연구자가 직접 레이블링(Labeling)하였고(Fig. 2(b)), 전통적인 분리 방법 중 성능이 우수한 영역 확장 방법(Fig. 2(c))과 지역 적응형 문턱치 처리(Fig. 2(d))를 적용하여 균열을 분리하였다. 그 결과 전통적인 분리 방법으로 추출된 균열의 두께와 거칠기가 직접 레이블링하여 얻은 균열에 비해 큰 것을 알 수 있다.

2.2 균열 추출을 위한 딥러닝
2.2.1 합성곱 신경망 기반 딥러닝 기법
영상 기반 딥러닝 기술은 컴퓨터 비전 분야에서 뛰어난 객체 인식 및 검출 성능으로 최근 주목받고 있다. 딥러닝의 기반이 되는 심층신경망(Deep neural network)의 개념은 1980년대에 제안되었으나, 신경망을 구성하는 수많은 매개변수를 학습시킬 충분한 데이터 확보의 문제와 학습에 필요한 연산량을 감당할 수 있는 하드웨어의 부재로 거의 사용되지 못했다. 이후 빅데이터가 확보되고 기존의 CPU(Central processing unit)보다 수십-수백 배 빠른 병렬 연산이 가능한 GPU(Graphics processing unit)가 개발되어 딥러닝을 이용한 연구가 가속화되었다.
본 연구에서 사용되는 CNN은 일반적으로 합성곱 층(Convolutional layer)과 풀링 층(Pooling layer)으로 구성된다. 합성곱 층은 합성곱 필터(Convolution filter)를 일정 간격으로 이동(Stride)해가며 영상 내 강인한 특징(Robust feature)을 추출하는 신경망 층이다. 이때 원하는 특징을 추출할 수 있도록 가중치(Weight)에 해당하는 합성곱 필터의 값을 학습(Training)할 수 있다. CNN은 하나의 필터를 입력 영상 전체에 사용함으로써 연결 가중치를 공유(Weight sharing)할 수 있어 학습할 매개변수의 수를 줄여 신경망 모델의 복잡성을 감소시킬 수 있다. 이에 반해 기존의 완전 연결 신경망(Fully- connected neural network)은 입력층(Input layer)과 출력층(Output layer)의 모든 노드(Node)들이 서로 연결되므로 2차원 영상이 입력되면 연결 가중치의 수가 증가함에 따라 연산량이 기하급수적으로 증가한다. 풀링 층은 신경망의 매개변수와 연산량을 줄이고 오버피팅(Overfitting)을 조절하기 위한 신경망 층이다. 풀링 층은 합성곱 필터에 비해 연산량이 훨씬 적게 소모되는 풀링 필터(Pooling filter)를 사용하는데, 주로 풀링 필터 내 하나의 최댓값을 추출하는 맥스 풀링(Max pooling)을 사용한다. 따라서 만약 사이즈가 2×2 이고 2칸씩 이동하는 풀링 필터를 사용하면 입력 영상에 비해 출력 영상의 크기가 1/4로 줄어들어 이후 연산량이 크게 감소한다. 또한, 학습을 위해 지정한 정답 레이블의 위치 변화가 발생해도 같은 특징으로 활성화되는 이동 불변성(Translation invariant)을 보장한다.
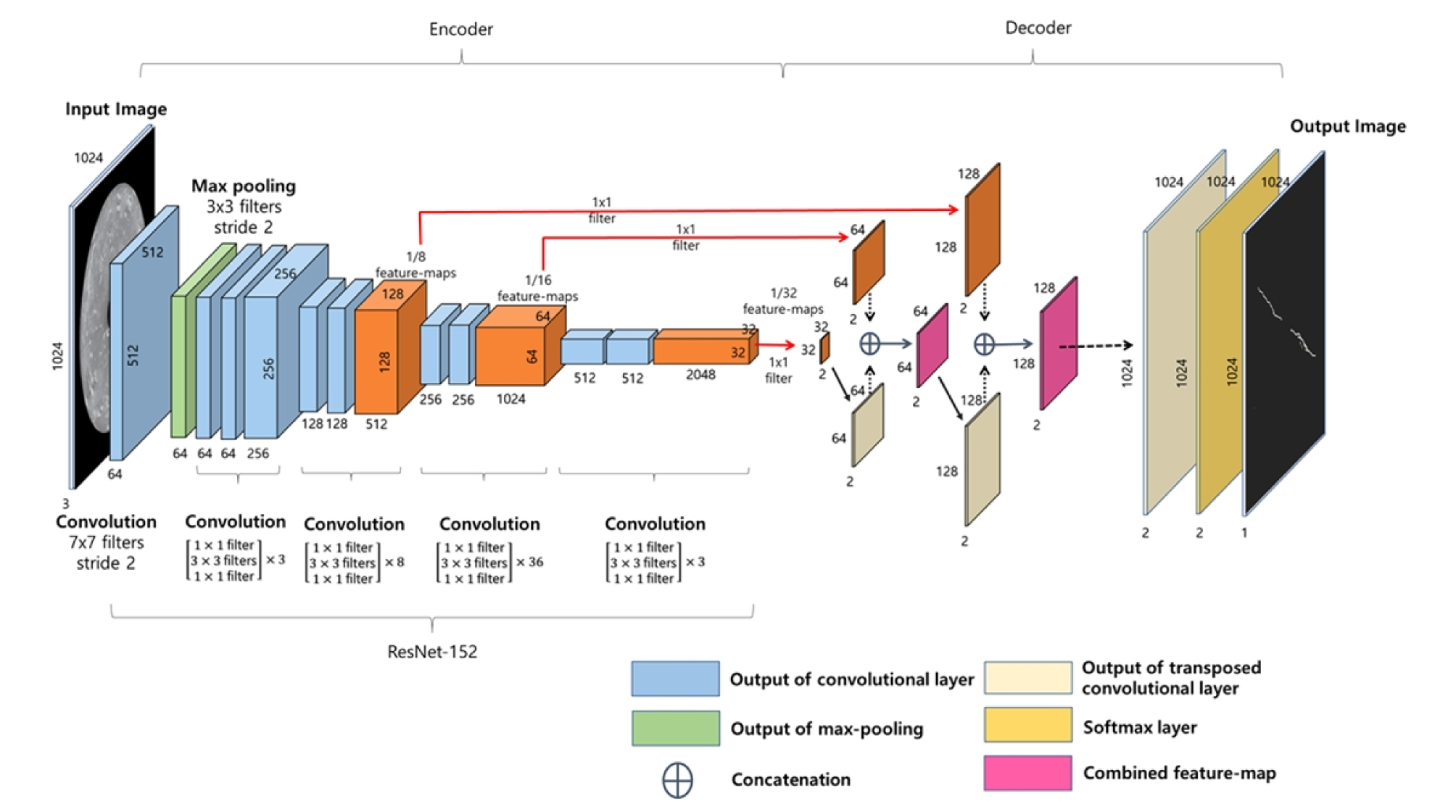
본 연구에서 추출하고자 하는 미세균열은 CT 영상 상에서 폭이 평균 1~3 픽셀이며 주변에 비슷한 밝깃값을 가지는 노이즈가 많아 높은 정확도의 기술이 요구된다. 따라서 검출하고자 하는 객체를 픽셀 단위까지 예측하여 의미 단위로 구획화(Semantic segmentation)할 수 있는 합성곱 신경망을 활용한 인코더-디코더(Encoder-Decoder) 구조를 적용하였다(Badrinarayanan et al., 2017).
2.2.2 인코더(Encoder)
인코더는 주로 합성곱 층과 풀링 층으로 구성되어 입력 영상에 포함된 특징 및 정보를 압축하는 특징 추출기 역할을 수행한다. 인코더를 훈련하기 위해서는 원본 영상과 추출하고자 하는 특징이 레이블링(Labeling) 된 영상이 한 쌍으로 구성된 데이터셋이 충분히 준비되어야 하지만, 일반적으로 정답 레이블(Label)을 포함하는 충분한 양의 학습 데이터셋을 구축하는 것은 매우 힘든 일이다. 따라서 이미지넷(ImageNet) 데이터셋과 같이 규모가 큰 데이터셋으로 미리 학습된(Pre-trained) 가중치를 가진 검증된 모델(e.g. AlexNet, GoogLeNet, VGG, ResNet 등)들을 사용하여 재학습을 통한 가중치의 미세 조정(Fine-tuning)만으로 충분한 성능을 도출해낼 수 있는 전이학습(Transfer learning)을 사용한다.
본 연구에서는 분류(Classification)와 검출(Detection) 분야에서도 높은 성능을 보여주는 ResNet 구조를 인코더로 선택하여 전이학습을 수행하였다(He et al., 2016). 픽셀 단위의 정밀한 균열 학습을 위해서는 인코더 단계에서의 특징 추출이 중요하므로, 여러 선행연구들에서 특징 추출기로서의 성능과 다양한 분야에서 적용 가능성이 검증된 ResNet-152(ResNet-152의 top-5 오차율: 3.6%, 훈련된 인간의 오차율: 5%)를 사용하였다. 합성곱 신경망으로 구성된 기존의 객체 분류 및 검출 모델은 말단부에 완전 연결 신경망을 포함하여 2차원 입력 영상을 1차원 벡터로 펼쳐야 하며, 이는 영상 데이터가 가지고 있는 위치 정보의 손실을 초래한다. 따라서 본 연구에서는 완전 연결 신경망 대신 1×1 크기의 합성곱 필터를 적용하여 입력 영상의 형태는 유지하면서 특징맵(Feature map)의 차원은 줄일 수 있는 완전 합성곱 신경망(Fully Convolutional Network; FCN)을 구성하였다(Long et al., 2015).
2.2.3 디코더(Decoder)
인코더를 통해 추출되고 압축된 특징 정보로부터 픽셀 단위 균열을 얻기 위해서는 디코더를 통한 원 영상 크기로의 복원 과정이 필요하다. 이때 디코더는 인코더의 출력에 대하여 합성곱 연산의 역연산 과정인 전치 합성곱 필터(Transposed convolution filter)를 적용하여 업샘플링(Upsampling)을 수행하고 균열 영상의 구획화를 가능케 한다(Noh et al., 2015). 하지만 인코더에서 여러 단계의 합성곱 층과 풀링 층을 통과하면 영상의 크기가 작아지면서 불가피한 정보 손실이 발생하게 되고 디코더의 업샘플링만으로 해당 영상의 크기를 복구하더라도 세부적인 정보가 손실된다. 따라서 본 연구에서는 정보 보존을 통한 픽셀 단위의 미세균열을 추출을 위해 인코딩 과정에서 생성한 특징맵을 디코딩 과정으로 연결하여 더해주는(Skip connection and concatenate) 방법을 추가한 디코더 모델을 제안하였다. 제안한 디코더를 통해 복원된 영상에 소프트맥스 활성화 함수(Softmax activation function)를 적용하여 균열 여부를 확률적으로 산출하였고 적절한 임계값(Thresholding)을 설정하여 이진화된 균열 영상을 획득하였다. 본 연구에서 인코더-디코더 기반 미세균열 추출을 위한 신경망 모델의 최종 구조는 Fig. 3과 같다.
3. 학습 데이터 구성
3.1 학습 및 테스트 데이터 (Training and test data)
일반적으로 딥러닝 모델을 사용하여 영상에서 균열을 탐지하기 위해서는 다양한 형상과 두께의 이미지에서 균열을 추출한 충분한 양의 학습 데이터가 필요하다. 특히 본 연구에서는 화강암의 X-ray CT 영상에서 미세균열을 추출해야 하므로 추가적인 학습 데이터 확보가 필수적이다. 따라서 화강암 X-ray CT 영상 원본에 대한 균열 레이블 데이터를 직접 생성하기 위해 3명의 인원을 투입해 최종적으로 111장의 데이터셋을 확보하였다. 하나의 영상 내 균열을 레이블 하는데 평균 15분 정도의 시간이 소모되었다. 학습 데이터셋과 테스트 데이터셋의 독립성을 보장하기 위해 각기 다른 화강암 시편으로부터 제작되었으며, 각각 90장과 21장으로 구성하였다. 또한, 영상 데이터 증대 기술을 통해 학습 데이터의 수를 증가시켜 효율적인 학습을 수행하였다.
3.2 영상 데이터 증대
딥러닝 기반 신경망 학습에서 학습 데이터가 부족한 경우, 사용한 데이터셋에 신경망 모델이 최적화되어 새로운 데이터(Unseen data)가 입력되었을 때 성능이 떨어지는 과적합 현상이 발생한다. 하지만 신경망 모델을 최적으로 학습시킬 수 있는 데이터의 수가 명시적으로 정해지지 않았을 뿐만 아니라 학습 데이터를 준비하는 데 시간을 비롯해 큰 비용이 소모된다. 따라서 충분히 많은 양의 학습 데이터를 직접 준비하기 어려운 경우, 영상 데이터 증대 기술을 통해 실제 학습에 사용되는 데이터 수를 증가시키는 방법이 주로 사용된다(Perez and Wang, 2017).
본 연구에서는 영상 분할(Division), 회전(Rotation), 그리고 반전(Flipping)을 이용하여 영상 증대 방법의 최적 조합을 찾기 위해 30장의 학습 데이터를 선별하였다. 각 조합의 성능 비교를 위해 전체 학습 데이터 수의 30%에 해당하는 검증 데이터(Validation data)에 대하여 정밀도(Precision), 재현율(Recall), 그리고 F-스코어(F-measure)를 계산하였다. 정밀도는 학습된 신경망이 균열로 예측한 픽셀이 실제 균열에 해당하는 픽셀의 비율을 나타내고(식 (1)) 재현율은 실제 균열 픽셀 중 신경망이 탐지한 픽셀의 비율을 나타낸다(식 (2)). 일반적으로 정밀도와 재현율은 서로 상충하는 관계이므로 두 값의 조화 평균으로 정의되는 F-스코어를 모델의 성능 평가 지표로 사용하기도 한다(식 (3)).
| $${\mathrm{Precision}\;}=\;\frac{True\;Positive}{True\;Positve\;+\;False\;Positive}$$ | (1) |
| $$Recall\;=\;\frac{True\;Positive}{True\;Positive\;+\;False\;negative}$$ | (2) |
| $$F-measure=\frac{2\bullet\mathrm{Precision}\bullet Recall}{\mathrm{Precision}+Recall}$$ | (3) |
4. 결과 및 분석
4.1 최적의 학습 데이터셋 선정
4.1.1 영상 분할
영상 분할에 의한 영상 증대 효과를 확인하기 위해, 1024×1024 크기의 원본 영상으로부터 4등분(512×512)과 16등분(256×256) 크기의 영상들을 생성하였다. 일반적으로 다층 퍼셉트론(Multi-layer neural network)을 이용하면 영상의 크기에 따라 학습해야 하는 매개변수의 개수가 기하급수적으로 증가하지만, CNN 기반 딥러닝 모델에서는 필터의 슬라이딩 윈도우(Sliding window) 방식에 의해 학습되므로 영상 크기에 비례하여 학습 시간이 증가하게 된다. 따라서 분할한 영상을 사용하면 학습 시간을 감소시킬 수 있다. 본 연구에서는 Table 1과 같이 입력 영상의 크기에 따라 영상 증대 방법의 조합들을 선정하여 검증하였다. 그 결과, 4등분과 16등분 영상만을 사용한 Table 1(b)와 1(c) 조합은 원본 영상만을 사용한 Table 1(a)에 비해 낮은 재현율을 보였다. 특히 Table 1(c)에서는 재현율이 정밀도보다 저조한 결과를 보였다. 실제 균열을 감지하지 못한 것(즉, 낮은 재현율)은 균열이 아닌 부분을 균열이라고 오판하는 경우(즉, 낮은 정밀도)보다 안전 관리 측면에서 바람직하지 않을 수 있다. 서로 다른 크기의 영상을 조합한 Table 1(d), 1(e), 1(f), 그리고 1(g)의 경우, 16등분 영상이 포함되어 전체 학습 데이터의 수는 증가했지만 성능은 감소하였다. 이는 16등분 분할로 인해 생성된 화강암 영상 중 균열을 포함하지 않는 영상의 비율이 급격히 증가하여 모델 학습에 부정적인 영향을 미친 것으로 판단된다. 결과적으로 본 연구에서는 입력 영상의 특징을 반영할 수 있는 영상 크기와 총 학습 시간을 고려할 때 원본 영상과 4등분으로 분할한 영상 간의 조합(Table 1(e))이 최적의 영상 분할 조합으로 판단된다.
Table 1. Crack detection performance by data augmentation using image division
4.1.2 영상 회전
X-ray CT 영상이 픽셀 단위로 구성되어 있어 임의 각도에 대해 균열 영상(즉, 이진 영상)을 회전하면 보간 과정에서 균열의 과대평가를 유발할 수 있다. 따라서 균열 자체의 변화를 주지 않기 위해 원본 영상으로부터 90°, 180°, 그리고 270° 회전만을 적용하여 성능을 비교하였다. Table 2는 원본 영상 30장에서 회전에 의한 영상 증대 효과를 관찰하기 위한 네 가지 조합을 나타낸 것으로, 원본 영상에 90° 회전 데이터셋을 추가한 경우가 성능이 가장 높게 나타났다. 또한, 최적의 영상 분할 조합(원본 영상 + 4분할 영상)에서 회전에 의한 영상 증대를 수행한 경우에서도 원본 영상에 90° 회전만을 추가한 조합이 상대적으로 높게 평가되었다(Table 3). 이는 영상 분할과 영상 회전이 일부 독립적으로 학습 성능을 향상 시킨다는 것을 의미한다.
Table 2. Crack detection performance by data augmentation using image rotation on the original 30 images
| (a) 0° rotation | (b) (0° + 90°) rotation |
(c) (0° + 90° + 180°) rotation |
(d) (0° + 90° + 180° + 270°) rotation | ||
| Validation | Precision | 56 | 62 | 60 | 58 |
| Recall | 63 | 66.2 | 64 | 64 | |
| F-measure | 59.3 | 64 | 62 | 61 | |
Table 3. Crack detection performance by data augmentation using image division and rotation
| (a) 0° rotation | (b) (0° + 90°) rotation |
(c) (0° + 90° + 180°) rotation |
(d) (0° + 90° + 180° + 270°) rotation | ||
| Validation | Precision | 70 | 65 | 61.3 | 62.3 |
| Recall | 68 | 77 | 75 | 75 | |
| F-measure | 69 | 70.5 | 67.5 | 68.1 | |
4.1.3 영상 반전
영상 반전에 의한 학습 데이터 증대 효과를 확인하기 위해 최적의 영상 회전 방법이 적용된 데이터셋(원본 영상 + 90° 회전 영상)에 영상 반전을 적용하였다(Table 4). 그 결과, 균열 추출의 목적에서 정밀도는 근소한 차이를 보이지만 Table 4(b)의 재현율이 크게 우세하였다. 따라서 영상 반전에 의한 균열 추출 성능 향상이 가능할 것으로 판단된다.
Table 4. Crack detection performance by data augmentation using image flipping
|
(a) (0° + 90°) rotation without flipping | (b) (0° + 90°) rotation with flipping | ||
| Validation | Precision | 62 | 61 |
| Recall | 66.2 | 74.5 | |
| F-measure | 64 | 67 | |
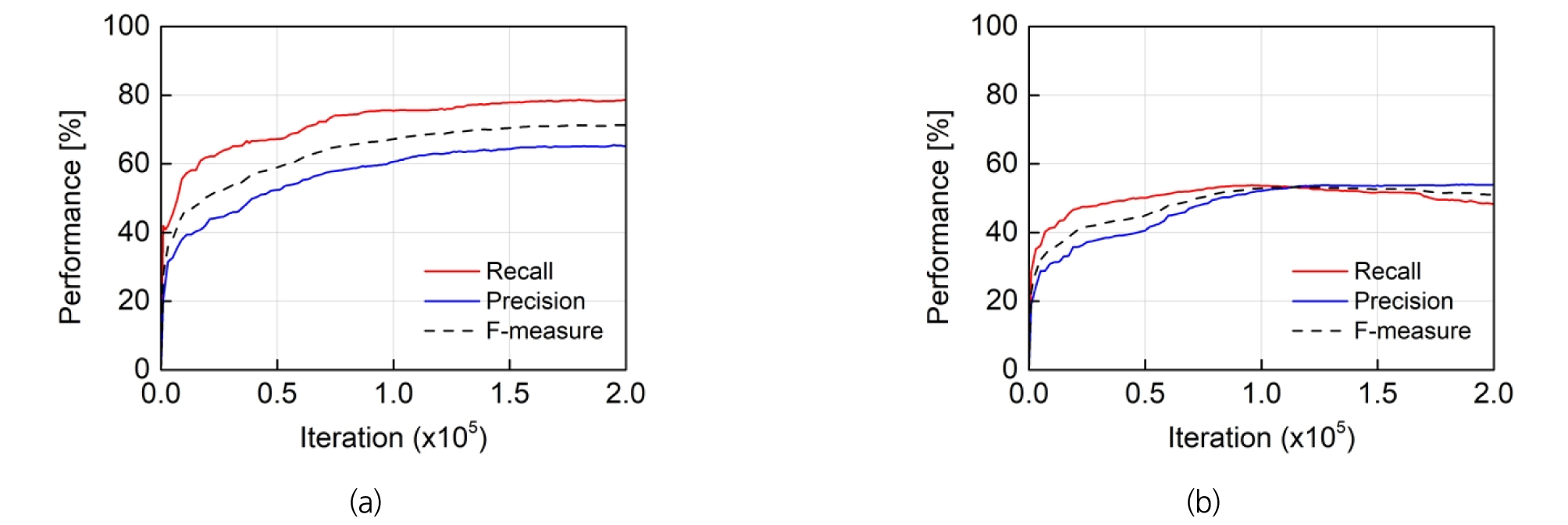
앞서 산정한 학습 데이터의 영상 증대 방법이 모델의 최종 성능에 미치는 영향을 고려하기 위해 영상 분할 조합, 회전, 반전을 순서대로 모두 적용한 결과(Fig. 4(a))와 적용하지 않은 결과(Fig. 4(b))를 비교하였다. 이때 각각의 성능 확인은 초기 학습 데이터의 30%에 해당하는 검증 데이터에 대해 수행했으며 신경망이 일정 횟수로 학습될 때마다 검증 데이터에 대하여 세 가지 성능 값(재현율, 정밀도, 그리고 F-스코어)을 계산하여 일정 값으로 수렴할 때까지 반복 학습이 수행되었다(200,000번). Fig. 4(a)는 원본 영상과 4분할 영상 조합에 90도 회전 영상을 추가한 후 이들의 반전 영상을 추가한 학습 데이터 증대 조합의 성능 결과로, 총 1800장의 초기 학습 데이터 중 1260장의 실제 학습 데이터로 신경망을 학습한 후 540장의 검증 데이터로 평가한 성능을 나타낸다. Fig. 4(b)는 원본 초기 학습 데이터 90장 중 63장의 실제 학습 데이터로 신경망을 학습한 후 27장의 검증 데이터로 평가한 성능을 나타낸다. 최적 영상 증대 조합(Fig. 4(a))에서는 재현율, 정밀도, 그리고 F-스코어가 최대 78.70%, 65.49%, 그리고 71.33%로 반복 학습이 진행하는 동안 꾸준히 성능이 향상됨을 확인할 수 있다. 반면, 원본 초기 학습 데이터만을 사용한 경우(Fig. 4(b)) 재현율, 정밀도, 그리고 F-스코어가 최대 53.80%, 53.94%, 그리고 53.31%로 현저히 낮은 성능을 나타내었다.
4.2 테스트 데이터 (Test data)
앞서 선정한 최적의 영상 증대 조합이 적용된 데이터로 학습된 신경망 모델의 최종 성능을 검증하였다. 이를 위해 원본 학습 데이터 수를 30, 60, 그리고 90장으로 선정하고, 21장의 데이터셋에 대해 테스트를 수행하였다(Fig. 5). 학습된 신경망 모델의 성능 평가 지표 중 하나인 F-스코어가 원본 학습 데이터 수가 늘어남에 따라 65.02%, 66.97%, 그리고 67.61%로 증가하였다. 따라서 영상 증대 방법으로 데이터 수가 증대되어도, 원본 학습 데이터 수에 따른 학습 데이터의 다양성이 신경망 모델의 최종 성능 향상에 중요하다는 점을 알 수 있다. 원본 데이터 개수의 증가에 따른 재현율 또는 정밀도의 급격한 향상은 관찰되지 않았으나, 의미 단위 구획화 문제는 성능 평가 지표가 민감하게 반응하여 성능 향상이 어려우므로 이러한 증가율은 의미 있는 경향성으로 판단된다. 또한, 균열을 픽셀 단위의 정밀도로 탐지하기 위한 학습 데이터를 평균 백 단위 이상으로 준비하였음을 기존 연구들을 통해 확인할 수 있다(Zhang et al., 2017, Yang et al., 2018, Bang et al., 2019). 따라서 원본 데이터 개수를 추가로 증가시킨다면 모델의 성능이 지속적으로 향상될 것으로 판단된다. 추가로 앞서 Fig. 4(a)의 신경망 모델 학습 과정에서 과적합 현상이 발견되지 않았음에도 불구하고 검증 데이터의 성능에 비해 테스트 데이터의 성능이 다소 낮게 나타났다.
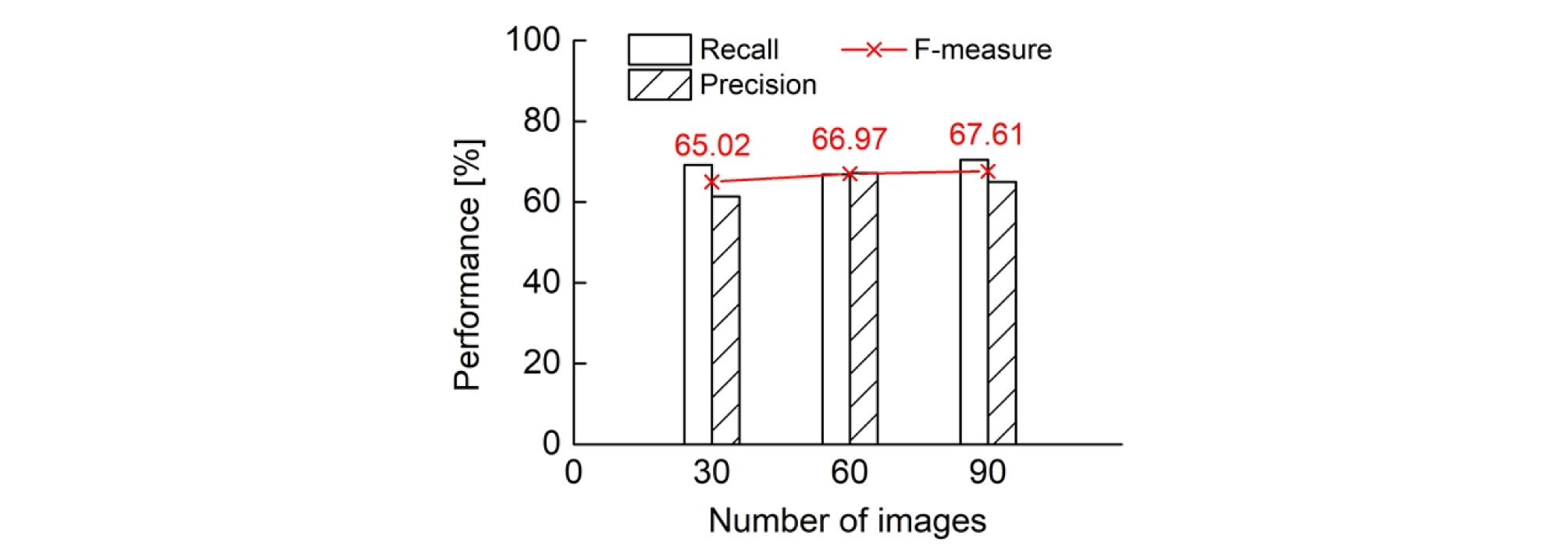
Fig. 6은 원본 영상에서 30, 90개의 원본 학습 데이터 수에 대해 최적 영상 증대로 학습된 신경망으로 추출된 균열 형상들과 연구자가 직접 레이블링한 균열을 비교하여 보여준다. 원본 데이터 30장을 사용한 추출 결과는 시추공 왼쪽의 중심 균열로부터 파생된 미세균열을 탐지하지 못했으나, 90장의 원본 데이터로 학습한 모델에서는 정답 레이블과 유사한 형태로 예측하였음을 확인할 수 있다. 마찬가지로 두 번째, 세 번째 행에서 확인할 수 있듯, 원본 데이터 90장으로 학습된 모델이 더욱 세부적인 균열 형태까지 예측할 수 있다.
원본 학습 데이터 90장에 최적 영상 증대 방법을 적용해 학습된 신경망으로 테스트 시편의 균열을 추출하였을 때 균열의 3차원 형상은 Fig. 7과 같다. 추출된 균열은 중간중간 구멍이 있지만, 전반적으로 하나의 연결된 균열 면(Fracture surface)을 형성하고 있다(Fig. 7(b)). 원통형 시편의 아래 혹은 가장자리로 갈수록 예측하지 못하는 균열 면의 영역이 존재하는데, 이는 신경망 학습 및 성능의 문제보다는 해당 영역 X-ray CT 영상에서의 한계로 판단된다.


5. 결 론
본 연구에서는 X-ray CT 촬영과 합성곱 기반 딥러닝 기법을 이용하여 수압파쇄로 생성한 화강암 시편 내 미세균열을 추출하였다. 이를 위해 합성곱 신경망 기반 인코더-디코더 구조의 ResNet-152 모델을 사용하였으며 미세균열 추출 성능 향상을 위한 디코더 모델을 제안하였다. 또한, 신경망 모델 학습에 사용되는 영상 데이터의 효율적인 생산을 위해 영상 증대 방법의 최적 조합을 확인하였으며, 이를 적용하여 원본 학습 데이터 수의 증가에 따른 딥러닝 모델의 균열 추출 성능의 변화를 분석하였다. 이를 통해 도출된 결론은 다음과 같다.
1) 영상의 밝깃값 차이에 기반한 알고리즘을 사용하는 기존 영상처리 방법으로는 화강암 X-ray CT 영상 내 육안으로만 확인 가능한 미세균열 추출이 불가능하다. 제안된 합성곱 신경망 기반 인코더-디코더 구조의 딥러닝 모델을 이용하면 픽셀 단위의 정밀한 균열 추출이 가능하고, 이를 이용하면 균열 형상의 정량적인 분석이 가능하다.
2) 최소 30장의 원본 학습 데이터에서도 전이학습과 영상 증대 방법을 적용한 학습으로 구현된 신경망은 비교적 정확한 균열 추출이 가능하였다.
3) 다양한 영상 증대 방법을 적용하여 본 연구에서 사용한 딥러닝 모델의 균열 추출 성능을 효율적으로 향상할 수 있는 최적의 조합을 확인하였으며, 생성한 학습 데이터의 원본 개수가 균열 추출 성능에 미치는 영향이 가장 크다는 사실을 확인하였다.
